Este artigo foi escrito utilizando o CTP de Novembro/2010 do SQL Server 2011 Denali.
O SQL Server code named “Denali” trás uma alternativa para a propriedade IDENTITY para o auto-incremento de valores, SEQUENCE. Para criar uma SEQUENCE temos o comando CREATE SEQUENCE, veja:
CREATE SEQUENCE Contador AS int
MINVALUE 1 NO MAXVALUE START WITH 1;
No comando acima foi criada uma SEQUENCE que inicia com o valor 1 e incremento de 1. Para testar execute o script abaixo:
SELECT NEXT VALUE FOR dbo.Contador as ClienteID
UNION ALL SELECT NEXT VALUE FOR dbo.Contador
UNION ALL SELECT NEXT VALUE FOR dbo.Contador
Resultado:
ClienteID
-----------
1
2
3
Para alterar o incremento para 5 basta utilizar o ALTER SEQUENCE e executar o mesmo SELECT acima para testar, veja:
ALTER SEQUENCE dbo.Contador RESTART WITH 1 INCREMENT BY 5;
SELECT NEXT VALUE FOR dbo.Contador as ClienteID
UNION ALL SELECT NEXT VALUE FOR dbo.Contador
UNION ALL SELECT NEXT VALUE FOR dbo.Contador
Resultado:
ClienteID
-----------
1
6
11
O SEQUENCE possui o mesmo comportamento do IDENTITY com relação a "gaps" na sequência de números gerados, no caso de ROLLBACK de uma transação, veja no exemplo abaixo:
ALTER SEQUENCE dbo.Contador RESTART WITH 1 INCREMENT BY 1;
BEGIN TRAN
SELECT NEXT VALUE FOR dbo.Contador as ProximoID;
ROLLBACK
SELECT ProximoID = NEXT VALUE FOR dbo.Contador;
O primeiro SELECT retorna 1 e o segundo 2, mesmo ocorrendo um ROLLBACK após o primeiro SELECT!
Quando utilizamos o IDENTITY temos a função IDENT_CURRENT() para retornar o valor corrente do IDENTITY em uma tabela, com o SEQUENCE execute o SELECT abaixo:
SELECT current_value FROM sys.sequences WHERE name = 'Contador'
Utilizar o SEQUENCE para gerar números seqüenciais automaticamente em uma tabela é muito simples veja:
CREATE SEQUENCE dbo.SEQ_Clientes AS int
MINVALUE 1 NO MAXVALUE START WITH 1;
CREATE TABLE dbo.Clientes
(ClienteID int not null DEFAULT NEXT VALUE FOR SEQ_Clientes,
Nome varchar(50) not null)
go
INSERT dbo.Clientes (Nome) VALUES ('Jose')
INSERT dbo.Clientes (Nome) VALUES ('Ana')
INSERT dbo.Clientes (Nome) VALUES ('Maria')
SELECT * FROM dbo.Clientes
Indicações de uso- A aplicação necessita saber o número antes de o INSERT ocorrer.
- A aplicação precisa compartilhar uma única numeração sequencial entre tabelas.
- Existe a necessidade de obter números seqüenciais (sem gap) para um conjunto de linhas (utilizar a Stored Procedure sp_sequence_get_range).
No próximo post farei uma comparação de desempenho entre IDENTITY e SEQUENCE,
Landry
quarta-feira, 1 de dezembro de 2010
quarta-feira, 24 de novembro de 2010
SQL Server 2011 cod named Denali CTP1
Com este post dou início a uma sequência de posts sobre a nova versão do Microsoft SQL Server code named “Denali”, que já estão chamando pela Internet de SQL Server 2011.
Segue abaixo link para download do primeiro CTP público:
http://www.microsoft.com/downloads/en/details.aspx?FamilyID=6a04f16f-f6be-4f92-9c92-f7e5677d91f9&displaylang=en
O SQL Server Denali possui os seguintes pré-requisitos para instalação (http://msdn.microsoft.com/en-us/library/ms143506(SQL.110).aspx):
- Sistemas Operacionais: Windows 7, Windows Server 2008 R2, Windows Server 2008 SP 2, Windows Vista SP 2.
- .NET Framework 3.5 SP1
- PowerShell 2.0 (http://support.microsoft.com/kb/968929/en-us)
Nos próximos posts irei explorar as novas funcionalidades, aguardem…
Landry
Segue abaixo link para download do primeiro CTP público:
http://www.microsoft.com/downloads/en/details.aspx?FamilyID=6a04f16f-f6be-4f92-9c92-f7e5677d91f9&displaylang=en
O SQL Server Denali possui os seguintes pré-requisitos para instalação (http://msdn.microsoft.com/en-us/library/ms143506(SQL.110).aspx):
- Sistemas Operacionais: Windows 7, Windows Server 2008 R2, Windows Server 2008 SP 2, Windows Vista SP 2.
- .NET Framework 3.5 SP1
- PowerShell 2.0 (http://support.microsoft.com/kb/968929/en-us)
Nos próximos posts irei explorar as novas funcionalidades, aguardem…
Landry
quinta-feira, 5 de agosto de 2010
Importando dados do SSAS utilizando SSIS
Olá... Neste post veremos como importar dados de um Cubo no Analysis Services (SSAS) utilizando o Integration Service (SSIS).
O primeiro passo é criar uma conexão para o SSAS dentro do pacote SSIS como abaixo:
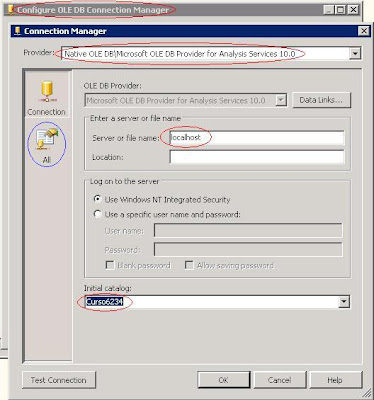
Em seguida clique em “All” (círculo azul da imagem acima) e entre com format=tabular na propriedade Extended Properties, veja na imagem abaixo:

Após configurar a conexão, utilize a tarefa Data Flow Task para extrair os dados do cubo. Importante lembrar que a linguagem utilizada para acessar Cubos é o MDX!

Você irá receber mensagens de advertência, pois o SSIS não consegue identificar os tipos de dados do SSAS, todas as colunas são retornadas como string. Em seguida utilize a transformação Data Conversion para converter os tipos de dados.
Outro problema é o Warning (símbolo de exclamação) no OLE DB Source, devido ao problema de não se identificar os tipos de dados no SSAS. Para retirar o Warning basta alterar a propriedade ValidateExternalMetadata para True.

Até o próximo post,
Landry
O primeiro passo é criar uma conexão para o SSAS dentro do pacote SSIS como abaixo:
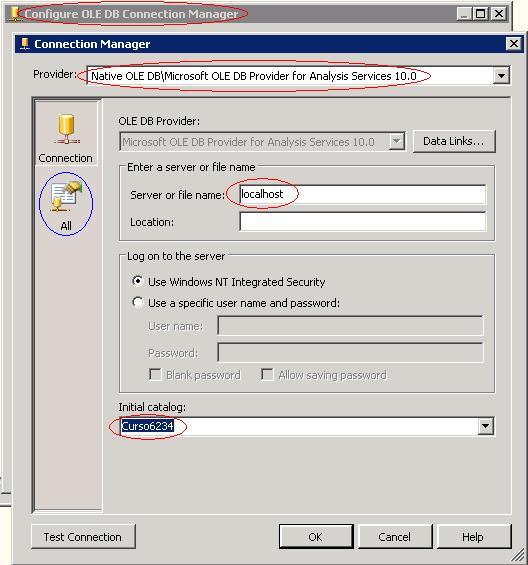
Em seguida clique em “All” (círculo azul da imagem acima) e entre com format=tabular na propriedade Extended Properties, veja na imagem abaixo:

Após configurar a conexão, utilize a tarefa Data Flow Task para extrair os dados do cubo. Importante lembrar que a linguagem utilizada para acessar Cubos é o MDX!

Você irá receber mensagens de advertência, pois o SSIS não consegue identificar os tipos de dados do SSAS, todas as colunas são retornadas como string. Em seguida utilize a transformação Data Conversion para converter os tipos de dados.
Outro problema é o Warning (símbolo de exclamação) no OLE DB Source, devido ao problema de não se identificar os tipos de dados no SSAS. Para retirar o Warning basta alterar a propriedade ValidateExternalMetadata para True.

Até o próximo post,
Landry
sexta-feira, 7 de maio de 2010
Clone de Banco de Dados para analisar plano de execução
Versões do SQL Server: 2005 e 2008.
Olá... o post de hoje é muito útil para quem trabalha com tuning de consultas, principalmente consultores!
Você é um consultor e precisa melhorar o desempenho de algumas consultas... Você terá que trabalhar no cliente porque este possui um banco de dados de 400GB de informações sigilosas! Bem, fazer Backup e levar para casa (ou escritório) é inviável devido ao tamanho do banco de dados e a necessidade de sigilo das informações. Uma alternativa é fazer um Clone do Banco de Dados levando a estrutura e as estatísticas de banco de dados, sem levar os dados. Um processo muito mais rápido que Backup e Restore, ocupa menos espaço em disco e resolve o problema do sigilo pois não leva os dados.
Para fazer um clone do Banco de dados basta entrar no Management Studio (SSMS), conectar na instância que contém o banco, expandir “Databases”, clicar com o botão direito no banco, selecionar “Tasks” e “Generate Scripts”.

Selecione o banco de dados e marque a opção “Script all objects in the selected database” como na figura abaixo:

Na próxima tela “Choose Script Options” altere algumas propriedades utilizando a tabela abaixo:

Na última tela gere o script para um arquivo qualquer, veja:

O próximo passo é editar o arquivo gerado... No início do arquivo, no comendo CREATE DATABASE altere o parâmetro SIZE do arquivo de dados e log para valores menores, pois não vamos ter os dados neste banco! Se for necessário altere a localização dos arquivos.
Agora basta executar o script (você verá alguns de GRANT para usuários inexistentes). Para conferir as estatísticas execute o DBCC SHOW_STATISTICS (,) para conferir! As tabelas estão vazias, mas as estatísticas refletem os dados da produção!
Pronto agora é só analisar as consultas, pois os planos de execução serão os mesmos da produção!
Até o próximo post,
Landry.
Olá... o post de hoje é muito útil para quem trabalha com tuning de consultas, principalmente consultores!
Você é um consultor e precisa melhorar o desempenho de algumas consultas... Você terá que trabalhar no cliente porque este possui um banco de dados de 400GB de informações sigilosas! Bem, fazer Backup e levar para casa (ou escritório) é inviável devido ao tamanho do banco de dados e a necessidade de sigilo das informações. Uma alternativa é fazer um Clone do Banco de Dados levando a estrutura e as estatísticas de banco de dados, sem levar os dados. Um processo muito mais rápido que Backup e Restore, ocupa menos espaço em disco e resolve o problema do sigilo pois não leva os dados.
Para fazer um clone do Banco de dados basta entrar no Management Studio (SSMS), conectar na instância que contém o banco, expandir “Databases”, clicar com o botão direito no banco, selecionar “Tasks” e “Generate Scripts”.

Selecione o banco de dados e marque a opção “Script all objects in the selected database” como na figura abaixo:

Na próxima tela “Choose Script Options” altere algumas propriedades utilizando a tabela abaixo:

Na última tela gere o script para um arquivo qualquer, veja:

O próximo passo é editar o arquivo gerado... No início do arquivo, no comendo CREATE DATABASE altere o parâmetro SIZE do arquivo de dados e log para valores menores, pois não vamos ter os dados neste banco! Se for necessário altere a localização dos arquivos.
Agora basta executar o script (você verá alguns de GRANT para usuários inexistentes). Para conferir as estatísticas execute o DBCC SHOW_STATISTICS (
Pronto agora é só analisar as consultas, pois os planos de execução serão os mesmos da produção!
Até o próximo post,
Landry.
segunda-feira, 26 de abril de 2010
Novidades T-SQL no SQL Server 2008 - Parte 3
Versão do SQL Server: 2008.
No dois últimos post escrevi sobre duas novidades relacionadas ao uso de variáveis e sobre o comando INSERT, veja nos links abaixo:
Neste terceiro post da série sobre as novidades do T-SQL no SQL Server 2008 veremos GROUPING SET. Até o SQL Server 2005 existiam 3 possibilidades de gerar subtotais em uma consulta, utilizando CUBE, ROLLUP e UNION, como vemos abaixo:
-- SQL 2005 ou inferior
select Cliente, NULL as Ano, sum(Valor) as Valor
from tmpCliente group by Cliente
UNION ALL
select NULL as Cliente, Ano, sum(Valor)
from tmpCliente group by Ano
UNION ALL
select NULL as Cliente, NULL as Ano, sum(Valor)
from tmpCliente
order by 1,2

Como resultado temos uma única consulta contendo:
Em Vermelho – total geral
Em Verde – subtotal por ano
Em azul – subtotal por cliente
No SQL Server 2008, para produzir o mesmo resultado, a consulta fica muito mais simples com GROUPING SET, veja:
select Cliente, Ano, sum(Valor)
from tmpCliente
group by grouping sets((Cliente),(Ano),())
order by 1,2
Até o próximo post,
Landry
No dois últimos post escrevi sobre duas novidades relacionadas ao uso de variáveis e sobre o comando INSERT, veja nos links abaixo:
Neste terceiro post da série sobre as novidades do T-SQL no SQL Server 2008 veremos GROUPING SET. Até o SQL Server 2005 existiam 3 possibilidades de gerar subtotais em uma consulta, utilizando CUBE, ROLLUP e UNION, como vemos abaixo:
-- SQL 2005 ou inferior
select Cliente, NULL as Ano, sum(Valor) as Valor
from tmpCliente group by Cliente
UNION ALL
select NULL as Cliente, Ano, sum(Valor)
from tmpCliente group by Ano
UNION ALL
select NULL as Cliente, NULL as Ano, sum(Valor)
from tmpCliente
order by 1,2

Como resultado temos uma única consulta contendo:
Em Vermelho – total geral
Em Verde – subtotal por ano
Em azul – subtotal por cliente
No SQL Server 2008, para produzir o mesmo resultado, a consulta fica muito mais simples com GROUPING SET, veja:
select Cliente, Ano, sum(Valor)
from tmpCliente
group by grouping sets((Cliente),(Ano),())
order by 1,2
Até o próximo post,
Landry
segunda-feira, 19 de abril de 2010
Novidades T-SQL no SQL Server 2008 - Parte 2
Versões do SQL Server: 2008.
No último post escrevi sobre duas novidades relacionadas ao uso de variáveis, veja neste link:
Neste post veremos uma opção bem interessante na instrução INSERT, a possibilidade de inclusão de múltiplos valores no mesmo comando INSERT.
Para começar vamos criar uma tabela no banco de dados TempDB utilizando o script abaixo:
use tempdb
go
create table tmpINSERT
(col1 int null, col2 varchar(10) null)
go
Para incluir 4 linhas na tabela tmpINSERT até o SQL Server 2005 utilizávamos o script abaixo:
-- SQL 2005 ou inferior
insert tmpINSERT (col1,col2) values (1,'linha 1')
insert tmpINSERT (col1,col2) values (2,'linha 2')
insert tmpINSERT (col1,col2) values (3,'linha 3')
insert tmpINSERT (col1,col2) values (4,'linha 4')
go
No SQL Server 2008 o script acima continua funcionando, porém temos agora uma opção mais simples veja:
-- SQL 2008
insert tmpINSERT (col1,col2) values
(1,'linha 1'),
(2,'linha 2'),
(3,'linha 3'),
(4,'linha 4')
go
Um único comando INSERT contendo uma lista de valores!
Até o próximo post,
Landry.
No último post escrevi sobre duas novidades relacionadas ao uso de variáveis, veja neste link:
Neste post veremos uma opção bem interessante na instrução INSERT, a possibilidade de inclusão de múltiplos valores no mesmo comando INSERT.
Para começar vamos criar uma tabela no banco de dados TempDB utilizando o script abaixo:
use tempdb
go
create table tmpINSERT
(col1 int null, col2 varchar(10) null)
go
Para incluir 4 linhas na tabela tmpINSERT até o SQL Server 2005 utilizávamos o script abaixo:
-- SQL 2005 ou inferior
insert tmpINSERT (col1,col2) values (1,'linha 1')
insert tmpINSERT (col1,col2) values (2,'linha 2')
insert tmpINSERT (col1,col2) values (3,'linha 3')
insert tmpINSERT (col1,col2) values (4,'linha 4')
go
No SQL Server 2008 o script acima continua funcionando, porém temos agora uma opção mais simples veja:
-- SQL 2008
insert tmpINSERT (col1,col2) values
(1,'linha 1'),
(2,'linha 2'),
(3,'linha 3'),
(4,'linha 4')
go
Um único comando INSERT contendo uma lista de valores!
Até o próximo post,
Landry.
sexta-feira, 16 de abril de 2010
Novidades T-SQL no SQL Server 2008 - Parte 1
Versões do SQL Server: 2008.
Estou iniciando uma sequência de posts sobre as novidades do T-SQL no SQL Server 2008. Nesta primeira parte veremos duas novidades:
1) Inicializar uma variável na sua declaração
Até o SQL Server 2005 se utilizava o comando DECLARE para declarar uma variável e depois o comando SET para atribuir um valor (inicializar). Veja no script abaixo:
-- SQL 2005 ou inferior
declare @i int
set @i = 1
select @i
No SQL Server 2008 o script acima continua funcionando, porém agora temos a opção de inicializar a variável junto da sua declaração, veja:
-- SQL 2008
declare @i int = 1
select @i
2) Operadores para incremento
Agora podemos incrementar uma variável utilizando a sintaxe da maioria das linguagens de programação, utilizando +=, veja:
declare @i int = 1
set @i += 1
select @i
Esta sintaxe vale também para outras operações:
+= soma e atribui
-= subtrai e atribui
*= multiplica e atribui
/= divide e atribui
%= Modulo e atribui
&= Bitwise AND e atribui
^= Bitwise XOR e atribui
= Bitwise OR e atribui
Até o próximo post,
Landry
Estou iniciando uma sequência de posts sobre as novidades do T-SQL no SQL Server 2008. Nesta primeira parte veremos duas novidades:
1) Inicializar uma variável na sua declaração
Até o SQL Server 2005 se utilizava o comando DECLARE para declarar uma variável e depois o comando SET para atribuir um valor (inicializar). Veja no script abaixo:
-- SQL 2005 ou inferior
declare @i int
set @i = 1
select @i
No SQL Server 2008 o script acima continua funcionando, porém agora temos a opção de inicializar a variável junto da sua declaração, veja:
-- SQL 2008
declare @i int = 1
select @i
2) Operadores para incremento
Agora podemos incrementar uma variável utilizando a sintaxe da maioria das linguagens de programação, utilizando +=, veja:
declare @i int = 1
set @i += 1
select @i
Esta sintaxe vale também para outras operações:
+= soma e atribui
-= subtrai e atribui
*= multiplica e atribui
/= divide e atribui
%= Modulo e atribui
&= Bitwise AND e atribui
^= Bitwise XOR e atribui
= Bitwise OR e atribui
Até o próximo post,
Landry
terça-feira, 13 de abril de 2010
Detectar Ausência de Backups em Produção
Versões do SQL Server: 7.0, 2000, 2005 e 2008.
Olá... Vou abordar um assunto simples, porém muito importante para “não abrir a vaga” do DBA: BACKUP.
Você precisa verificar se todos os bancos de dados dos servidores em produção estão com os backups em dia, o que fazer? Colocar simplesmente um alerta no JOB de backup para quando ocorrer uma falha não basta, porque pode existir um banco novo que ainda não tem JOB de backup... Ou então se o JOB de backup foi desabilitado?
Existe um método simples de verificar consultando a tabela backupset no banco de dados de sistema MSDB. Veja a consulta abaixo:
select b.database_name as Banco,b.backup_finish_date as UltimoBackup,
case b.[type]
when 'D' then 'Database'
when 'I' then 'Database Differential'
when 'L' then 'Log'
when 'F' then 'File or Filegroup'
end as TipoBackup -- b.*
from msdb.dbo.backupset b join
(select database_name, max(backup_finish_date) backup_finish_date
from msdb.dbo.backupset group by database_name) u
on b.database_name = u.database_name and b.backup_finish_date = u.backup_finish_date
where b.backup_finish_date < (getdate() - 2) or b.backup_finish_date is null order by b.database_name
A consulta acima retorna uma lista com os bancos de dados onde o último backup feito (não importa o tipo) é anterior a dois dias da data corrente.
Para obter a lista dos bancos de dados sem backup nos últimos 2 dias, basta comparar o resultado da consulta acima com a view sysdatabases, veja:
with BackupFeito as (
select b.database_name as Banco
from msdb.dbo.backupset b join
(select database_name, max(backup_finish_date) backup_finish_date
from msdb.dbo.backupset group by database_name) u
on b.database_name = u.database_name and
b.backup_finish_date = u.backup_finish_date
where b.backup_finish_date < (getdate() - 2) or b.backup_finish_date is null) select name as Banco from sysdatabases s where s.name not in('tempdb','model') and not exists (select * from BackupFeito b where b.Banco = s.name)
Basta rodar esta consulta em cada servidor para obter a listagem dos bancos de dados sem backup nos últimos 2 dias! Você pode automatizar utilizando Linked Server ou PowerShell. Se você estiver no SQL Server 2008 poderá utilizar o recurso de execução de scripts em múltiplas instâncias, veja no post:
http://sqlserver-brasil.blogspot.com/2008/03/executando-scripts-em-mltiplas.html.
Até o próximo post,
Landry
Olá... Vou abordar um assunto simples, porém muito importante para “não abrir a vaga” do DBA: BACKUP.
Você precisa verificar se todos os bancos de dados dos servidores em produção estão com os backups em dia, o que fazer? Colocar simplesmente um alerta no JOB de backup para quando ocorrer uma falha não basta, porque pode existir um banco novo que ainda não tem JOB de backup... Ou então se o JOB de backup foi desabilitado?
Existe um método simples de verificar consultando a tabela backupset no banco de dados de sistema MSDB. Veja a consulta abaixo:
select b.database_name as Banco,b.backup_finish_date as UltimoBackup,
case b.[type]
when 'D' then 'Database'
when 'I' then 'Database Differential'
when 'L' then 'Log'
when 'F' then 'File or Filegroup'
end as TipoBackup -- b.*
from msdb.dbo.backupset b join
(select database_name, max(backup_finish_date) backup_finish_date
from msdb.dbo.backupset group by database_name) u
on b.database_name = u.database_name and b.backup_finish_date = u.backup_finish_date
where b.backup_finish_date < (getdate() - 2) or b.backup_finish_date is null order by b.database_name
A consulta acima retorna uma lista com os bancos de dados onde o último backup feito (não importa o tipo) é anterior a dois dias da data corrente.
Para obter a lista dos bancos de dados sem backup nos últimos 2 dias, basta comparar o resultado da consulta acima com a view sysdatabases, veja:
with BackupFeito as (
select b.database_name as Banco
from msdb.dbo.backupset b join
(select database_name, max(backup_finish_date) backup_finish_date
from msdb.dbo.backupset group by database_name) u
on b.database_name = u.database_name and
b.backup_finish_date = u.backup_finish_date
where b.backup_finish_date < (getdate() - 2) or b.backup_finish_date is null) select name as Banco from sysdatabases s where s.name not in('tempdb','model') and not exists (select * from BackupFeito b where b.Banco = s.name)
Basta rodar esta consulta em cada servidor para obter a listagem dos bancos de dados sem backup nos últimos 2 dias! Você pode automatizar utilizando Linked Server ou PowerShell. Se você estiver no SQL Server 2008 poderá utilizar o recurso de execução de scripts em múltiplas instâncias, veja no post:
http://sqlserver-brasil.blogspot.com/2008/03/executando-scripts-em-mltiplas.html.
Até o próximo post,
Landry
terça-feira, 6 de abril de 2010
Volume de IO por Banco de Dados
Versões do SQL Server: 2005 e 2008.
Após um longo período sem publicar posts estou de volta... Venho publicando vários posts extensos que demandavam muito tempo de pesquisa e escrita, resultando neste longo período de inatividade. Resolvi publicar posts menores, mais simples, abortando temas relacionados ao meu dia a dia como consultor.
Uma instância do SQL Server pode ter vários bancos de dados, seria muito útil para o DBA ter informações estatísticas da atividade de cada banco. Um modo simples de obter estatísticas de IO é o uso da função dinâmica de sistema sys.dm_io_virtual_file_stats. Rode o script abaixo no seu servidor:
with IO_por_Banco as (
select db_name(database_id) as Banco,
cast(sum(num_of_bytes_read + num_of_bytes_written) / 1048576 as decimal(12,2))
as IO_Total_MB,
cast(sum(num_of_bytes_read) / 1048576 as decimal(12,2)) as IO_Leitura_MB,
cast(sum(num_of_bytes_written) / 1048576 as decimal(12,2)) as IO_Escrita_MB
from sys.dm_io_virtual_file_stats(NULL,NULL) as dm
group by database_id)
select row_number() over (order by IO_Total_MB DESC) as Ranking,
Banco, IO_Leitura_MB, IO_Escrita_MB,
IO_Total_MB, cast(IO_Total_MB / sum(IO_Total_MB) over() * 100 as decimal(5,2))
as Percentual
from IO_por_Banco
order by Ranking
O resultado traz o ranking por volume de IO do maior para o menor. O DBA pode utilizar estas informações para planejar a realocação de bancos entre servidores, ou em um projeto de consolidação.
Até o próximo post,
Landry.
Após um longo período sem publicar posts estou de volta... Venho publicando vários posts extensos que demandavam muito tempo de pesquisa e escrita, resultando neste longo período de inatividade. Resolvi publicar posts menores, mais simples, abortando temas relacionados ao meu dia a dia como consultor.
Uma instância do SQL Server pode ter vários bancos de dados, seria muito útil para o DBA ter informações estatísticas da atividade de cada banco. Um modo simples de obter estatísticas de IO é o uso da função dinâmica de sistema sys.dm_io_virtual_file_stats. Rode o script abaixo no seu servidor:
with IO_por_Banco as (
select db_name(database_id) as Banco,
cast(sum(num_of_bytes_read + num_of_bytes_written) / 1048576 as decimal(12,2))
as IO_Total_MB,
cast(sum(num_of_bytes_read) / 1048576 as decimal(12,2)) as IO_Leitura_MB,
cast(sum(num_of_bytes_written) / 1048576 as decimal(12,2)) as IO_Escrita_MB
from sys.dm_io_virtual_file_stats(NULL,NULL) as dm
group by database_id)
select row_number() over (order by IO_Total_MB DESC) as Ranking,
Banco, IO_Leitura_MB, IO_Escrita_MB,
IO_Total_MB, cast(IO_Total_MB / sum(IO_Total_MB) over() * 100 as decimal(5,2))
as Percentual
from IO_por_Banco
order by Ranking
O resultado traz o ranking por volume de IO do maior para o menor. O DBA pode utilizar estas informações para planejar a realocação de bancos entre servidores, ou em um projeto de consolidação.
Até o próximo post,
Landry.
Assinar:
Postagens (Atom)